Grammatically, parentheses must be balanced, meaning every open parenthesis ‘(‘ must eventually be followed by a close parenthesis ‘)’. Parentheses can be nested, meaning there can be parentheses inside parentheses. If we were to take a piece of writing and remove all letters and punctuation except parentheses, we might end up with something like: ()()()(())()(), in other words a string of balanced parentheses. The set of all possible such strings is known as the language of balanced parentheses. This is a formal, “context-free” language which can be described mathematically. If a string of parentheses is balanced, we say it’s included in the language of balanced parentheses.
The Chomsky language hierarchy and automata
There are different kinds of formal languages, distinguished (roughly speaking) by how complex the language is. The simplest is a regular language, which can be described using a regular expression (“regex”), a type of string pattern-matching. A regular language is a special case of a context-free language, which is a special case of a context-sensitive language, which is a special case of a recursively enumerable language. This is called the Chomsky hierarchy. As mentioned, the language of balanced parentheses is a context-free language.
A formal language can be characterized completely by an automaton, a mathematical abstraction of a computer, that is capable of deciding whether an input string is in the language or not. Since such an automaton accepts all and only strings in that language, it is called an acceptor for the language. Different types of automata exist and are distinguished (roughly speaking) by how powerful they are. A Turing machine, which essentially represents anything a computer is theoretically capable of, is a very general type of automaton.
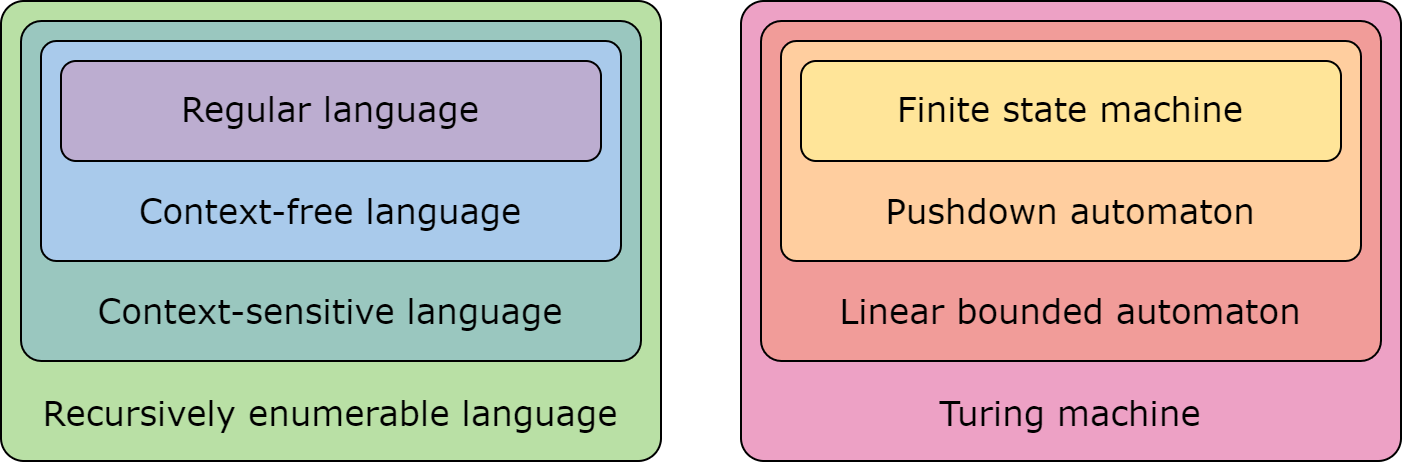
The acceptor for a context-free language is called a pushdown automaton, “pushdown” here referring to the presence of a memory stack. A stack is a list in which only the top item is accessible and new items are added onto the top. It is a “first in, last out” model. The language used in computer science to describe how a stack works is in analogy to a cafeteria tray dispenser: a new item can be “pushed” onto the top of the stack or the top item on the stack can be “popped” off, hence the term “pushdown automaton.”
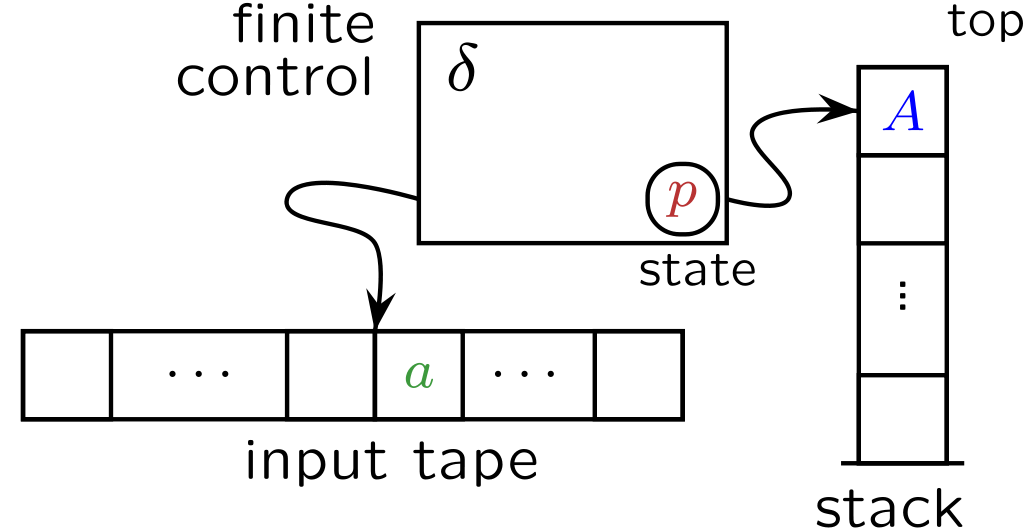
The acceptor for the language of balanced parentheses works as follows. We read in the input string character-by-character from left to right. Every time we read a ‘(‘, push it onto the stack. Every time we read a ‘)’, pop the top item off the stack. If the last character of the input string is ‘)’ and pops the last item off the stack, then we accept the string. If the stack is not empty when we’re done reading the input, or if we encounter a ‘)’ when the stack is empty, then we reject the string. This algorithm can easily be implemented in code:
def pda():
stack = list()
string = input()
for character in string:
if character == '(':
stack = [character] + stack
elif character == ')':
if len(stack) == 0:
return False
else:
stack.pop()
if len(stack) > 0:
return False
return TrueNote that this algorithm runs in linear time, or O(n). This means that the number of computation steps required is asymptotically bounded by a linear function of the input string’s length. More simply put, the time required to determine if a string should be accepted or rejected is proportional to the length of the string.
Representation as lattice paths
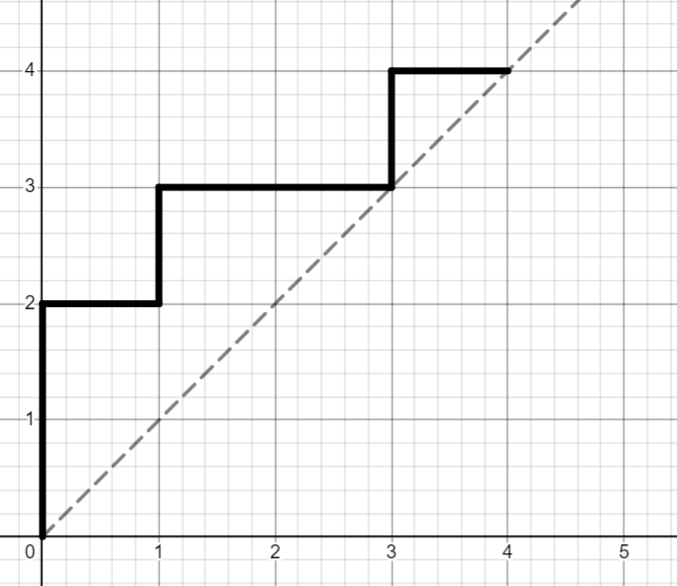
A string of parentheses can be represented as a lattice path (or staircase walk) in the following way: starting from (0,0) and reading the string from left to right, step 1 unit up when encountering a ‘(‘ and step 1 unit right when encountering a ‘)’. If the string is balanced, then the entire path must lie above the diagonal and must end on the diagonal.
Alternatively, we could step up and to the right for every ‘(‘ and down and to the right for every ‘)’, in which case a balanced string must stay above the horizontal axis and must end on the horizontal axis.
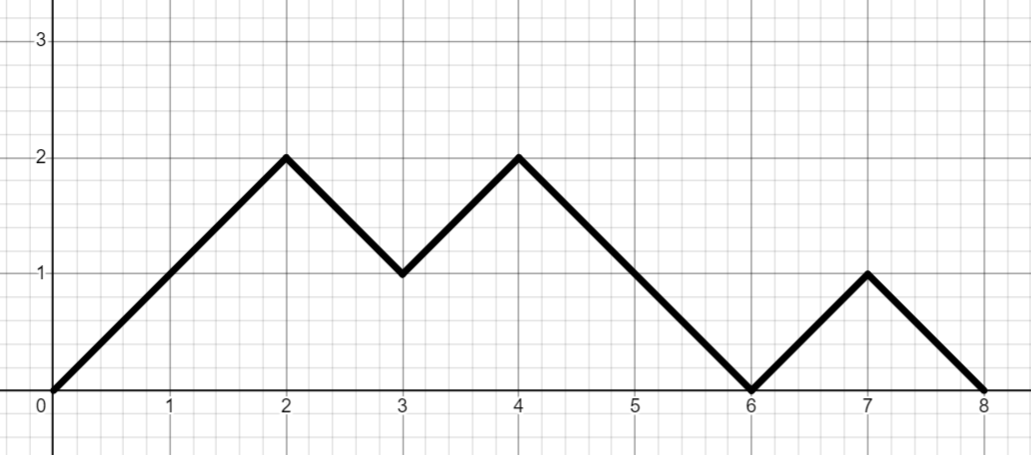
These are called Dyck paths and are a special case of Motzkin paths.
Investigating the language
One question we might want to ask is, how many strings of length n exist in the language of balanced parentheses? First of all, it is immediately clear that the answer is zero when n is an odd number. In order for parentheses to be balanced, there must be an equal number of open and close parentheses, and so the length must be even. A better question, then, might be how many strings of length 2n exist, since for any n greater than zero there will be more than zero strings.
We can begin by counting all the possibilities for small values of n.
| n | Possible strings of balanced parentheses of length 2n |
| 1 | () |
| 2 | ()(), (()) |
| 3 | ()()(), (())(), ()(()), ((())), (()()) |
Beyond this point, counting by hand becomes difficult.
Let’s think about counting Dyck paths using the Motzkin path representation. We can break the problem down by counting the number of paths of length 2n with k peaks, where 1 ≤ k ≤ n. We can easily observe that there is only one possible path with n peaks and only one path with 1 peak.
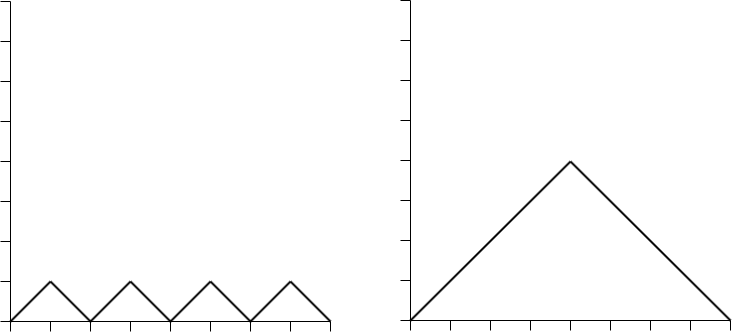
Now, if we consider n = 4 and k = 2, we get 6 paths:
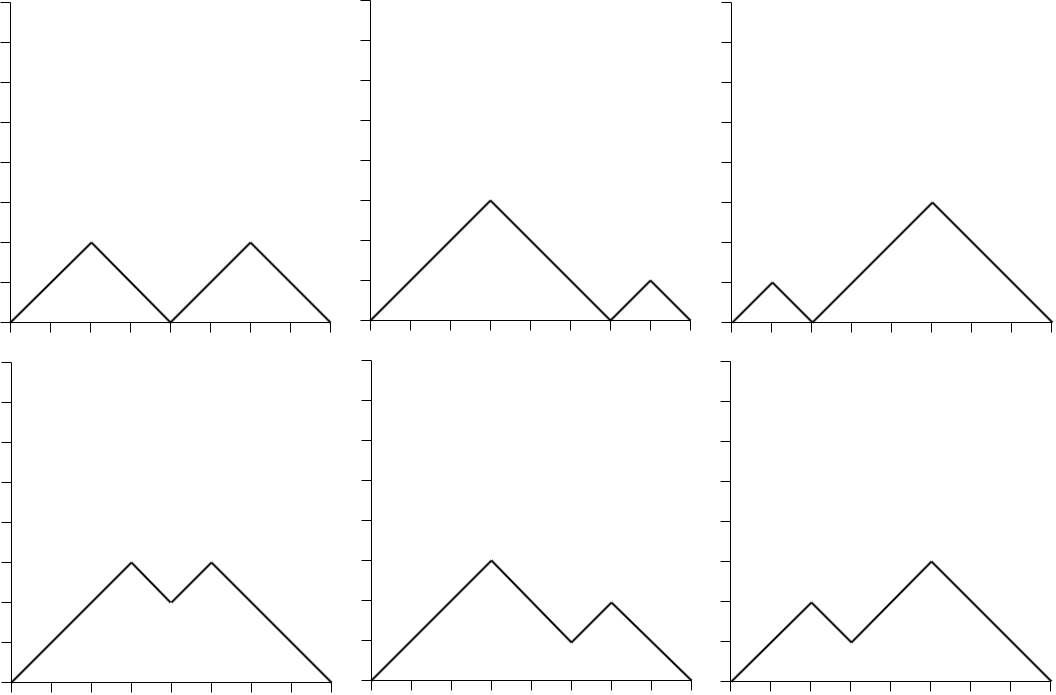
Similarly for k = 3:
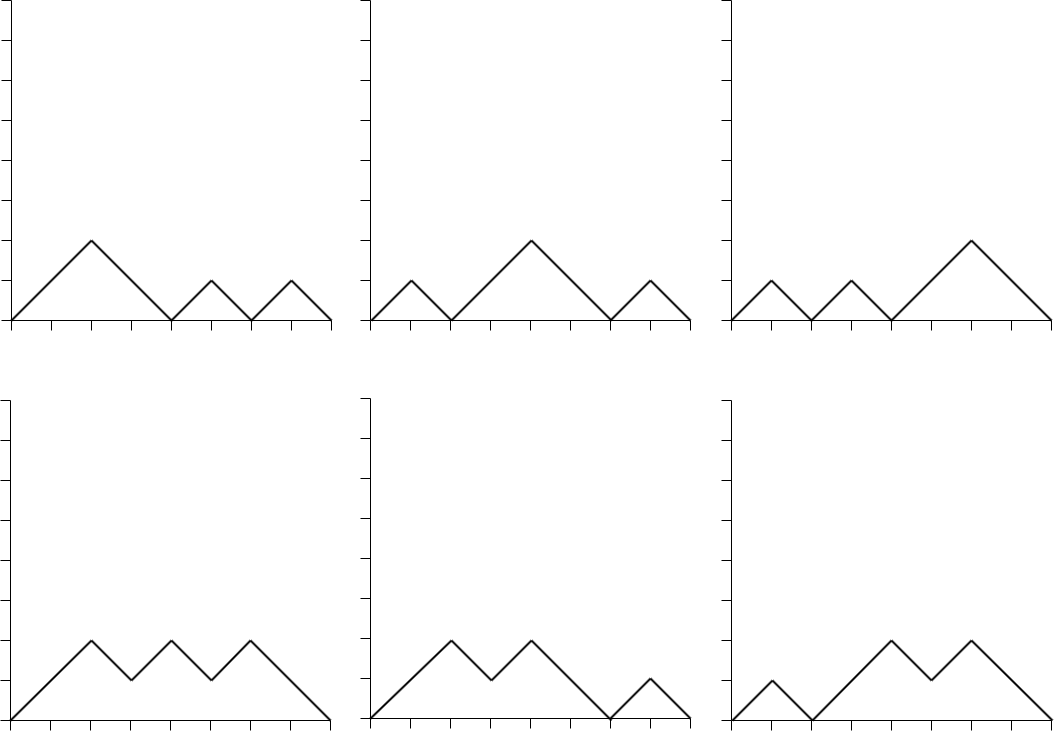
So, for k = 1, 2, 3, 4 we get 1, 6, 6, 1 possible paths. These values turn out to be given by the Narayana numbers:
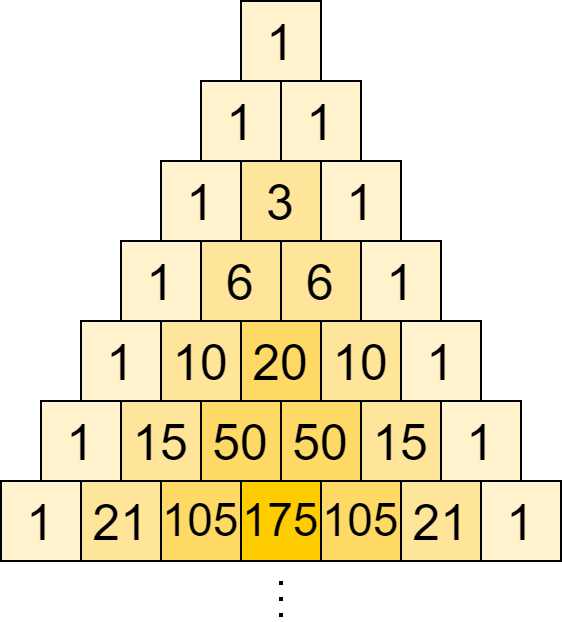
The sum of each row of this triangle, then, is the total number of possible strings of balanced parentheses. These are the Catalan numbers.
| k = 1 | 2 | 3 | 4 | 5 | 6 | Sum (Catalan number) | |
| n = 1 | 1 | 1 | |||||
| 2 | 1 | 1 | 2 | ||||
| 3 | 1 | 3 | 1 | 5 | |||
| 4 | 1 | 6 | 6 | 1 | 14 | ||
| 5 | 1 | 10 | 20 | 10 | 1 | 42 | |
| 6 | 1 | 15 | 50 | 50 | 15 | 1 | 132 |
The nth Catalan number is given by the following formula:
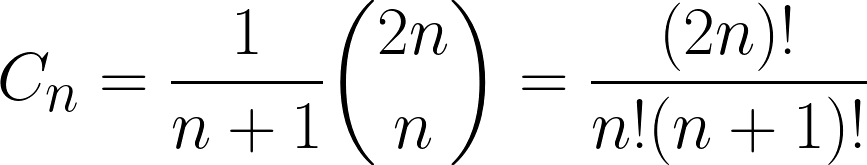
The fact that there are Cn Dyck paths of length 2n is called the Chung-Feller theorem. There are several different proofs of this theorem.
Now, why is this information useful? For one, the Catalan numbers come up very frequently in combinatorics when talking about things like probabilities and data structures. Two things being equal in number means that there exists a bijection, or one-to-one correspondence, between them. In math, bijections are a special relationship that certain mathematical structures have. Knowing about structures that are in bijection with the structure you’re studying is useful for proving theorems. We saw for example that balanced parentheses and Dyck paths are in bijection and that helped us to count strings of balanced parentheses.
The entry on the On-line Encyclopedia of Integer Sequences (OEIS) gives more examples of things the Catalan numbers enumerate, including:
OEIS sequence A000108
- The number of ways to place n indistinguishable balls in n numbered boxes B1,…,Bn such that at most a total of k balls are placed in boxes B1,…,Bk for k=1,…,n. For example, a(3)=5 since there are 5 ways to distribute 3 balls among 3 boxes such that (i) box 1 gets at most 1 ball and (ii) box 1 and box 2 together get at most 2 balls:(O)(O)(O), (O)()(OO), ()(OO)(O), ()(O)(OO), ()()(OOO). – Dennis P. Walsh, Dec 04 2006
- a(n) is also the order of the semigroup of order-decreasing and order-preserving full transformations (of an n-element chain) – now known as the Catalan monoid. – Abdullahi Umar, Aug 25 2008
- a(n) is the number of trivial representations in the direct product of 2n spinor (the smallest) representations of the group SU(2) (A(1)). – Rutger Boels (boels(AT)nbi.dk), Aug 26 2008
- The invert transform appears to converge to the Catalan numbers when applied infinitely many times to any starting sequence. – Mats Granvik, Gary W. Adamson and Roger L. Bagula, Sep 09 2008, Sep 12 2008
Limit_{n->oo} a(n)/a(n-1) = 4. – Francesco Antoni (francesco_antoni(AT)yahoo.com), Nov 24 2008- Starting with offset 1 = row sums of triangle A154559. – Gary W. Adamson, Jan 11 2009
- C(n) is the degree of the Grassmannian G(1,n+1): the set of lines in (n+1)-dimensional projective space, or the set of planes through the origin in (n+2)-dimensional affine space. The Grassmannian is considered a subset of N-dimensional projective space, N = binomial(n+2,2) – 1. If we choose 2n general (n-1)-planes in projective (n+1)-space, then there are C(n) lines that meet all of them. – Benji Fisher (benji(AT)FisherFam.org), Mar 05 2009
Example: finding abelian borders
Abelian borders are a type of string pattern. A string is said to have a border if it has a prefix and suffix that are the same. For example, the string “shush” has the border “sh.” An abelian border is like a border, but the letters may be in a different order. For example, the string “kayak” has the border “k” and the abelian borders “k,” “ka,” and “kay.” The string “abcdbac” has no borders but it has abelian borders “abc” and “abcd.” The string “wxyz” has neither borders nor abelian borders.
Notice that strings can often have multiple abelian borders. The one that is shortest in length is called the minimal abelian border. Some examples of questions we can ask, then, are “How many strings of length n have a minimal abelian border of length k?” and “How many strings of length n have m distinct abelian borders?”
Let’s consider a binary alphabet consisting of 0s and 1s. This is essentially the same as our alphabet consisting of ‘(‘ and ‘)’, just with different symbols. As a result, we can use the bijection between strings of balanced parentheses and lattice paths to answer the questions above. This is something we did in the paper I coauthored. The proofs of the following theorems can be found there. This is the power of bijection in action!
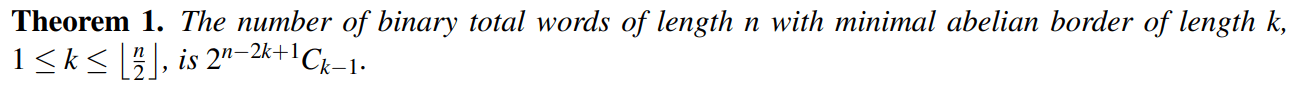
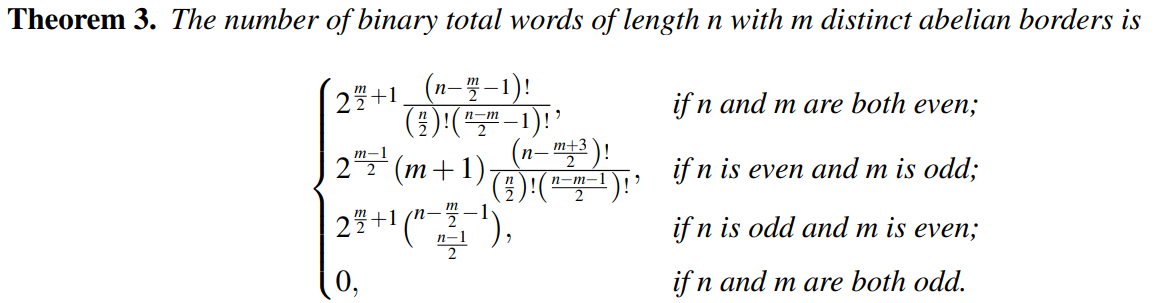

{kind=link}